
こんにちは。
やらしみずです。
前回作成したアニメの総時間を調べるPythonのコード、少し書き方が気持ち悪かったのと機能がしょぼかったので修正しました。
アニメ作品数とかもちゃんと出るようにしました!!
全コード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
# coding: UTF-8 from urllib.request import urlopen from urllib.parse import unquote from bs4 import BeautifulSoup import csv import re # 今回求めた結果を入れる変数 sum_anime_title = 0 sum_anime_story =0 # wikiのURL 取得したhrefに正しくアクセスするために利用 wiki_url = "https://ja.wikipedia.org" # アニメの一覧が載っているURL root_url = "https://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E3%81%AE%E3%83%86%E3%83%AC%E3%83%93%E3%82%A2%E3%83%8B%E3%83%A1%E4%BD%9C%E5%93%81%E4%B8%80%E8%A6%A7" # html情報をすべて取得 html = urlopen(root_url) # Bs4で扱える状態にする soup = BeautifulSoup(html, "html.parser") # ulをすべて取得する uls = soup.findAll("ul") # アクセスするURLの一覧を配列として保存する url_list = [] # 取得したulから必要なリンク情報を取得する for ul in uls: csvRow = [] # 作品一覧の家で必要なリンクを絞り込み for link_title in ul.findAll("li", text = re.compile("日本のテレビアニメ作品一覧.*\)")): url_list.append(link_title.find("a").get("href")) # 取得したリンクからデータを所得していく。 for url in url_list: calc_num = 0 print(unquote(url)+" データ取得中...") # 取得したデータを保存しておくためのファイルを開く ※計算までこのプログラムで行うので必要は無いが他に役立つかもしれないので一応残留 csvFileTitle = unquote(url.lstrip("/wiki/"))+".csv" csvFile = open(csvFileTitle, 'w', encoding = 'utf-8') writer = csv.writer(csvFile) # URLにアクセスする 全htmlが帰ってくる html = urlopen(wiki_url+url) # Bs4で扱える状態にする soup = BeautifulSoup(html, "html.parser") # 利用するテーブルを取得する 今回は「wikitable」という名前だったのでこちらを利用 tables = soup.findAll("table",{"class":"wikitable"}) try: # table→tr→tdと階層を降りていく for table in tables: rows = table.findAll("tr") for row in rows: csvRow = [] for cell in row.findAll("td"): # 保存するためのリストを作成する csvRow.append(cell.get_text().strip()) # 不要なデータを計算に入れないために、データが入ってないセルの場合は書き込まない。 if csvRow != []: # 総タイトル数を計算 sum_anime_title += 1 # 総話数を計算 # 不要な文字列と数字を削除する story_num = re.sub(r'\[.*\]', '', str(csvRow[4])).strip() story_num = re.sub(r'\D', '', str(story_num).strip()) if story_num != '': sum_anime_story += int(story_num) # 1タイトルごとに書き込みを行う writer.writerow(csvRow) calc_num += 1 print(unquote(url)+str(calc_num) + " 年分の計算完了") print(unquote(url)+" 正常にデータを取得しました\n") except Exception as e: print("例外:", e.args) print(unquote(url)+" データの取得に失敗しました。。。。\n") finally: csvFile.close() # 結果出力 print("\n\n======== 結果 =========\n") print("■ 総アニメタイトル数:"+str(sum_anime_title)+"タイトル"+"\n") print("■ 総アニメ話数 :"+str(sum_anime_story)+"話"+"\n") print("■ 総放送時間 :"+str(sum_anime_story/2)+"時間\n") print("======================") |
前回からの修正点
前回のものと大筋は変わっていません。
PythonのライブラリbeautifulSoupを使って、Wikipediaさんからアニメの一覧を引っぱってきて、話数×30分で計算しています。
・ルートのURLを指定することで新しいページが出来た場合に対応
・アニメ作品数をタイトルとして計算・出力
・保存するcsvファイルはページごとに変更
・保存する際に改行がおかしかったのを修正(リストの初期化ミス)
・計算結果を出力するところまでを自動化
・ほんの気持ち程度のエラー対応
再計算結果!!
せっかく作成したので、再度計算を行って見ました。
結果
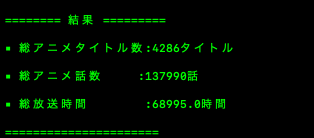
前回アニメの総時間を計算した際には、総数4286話、62407時間という計算結果だったので、おそらく間違えていましたね笑
手動で不必要なデータのはじき出しとかを行っていたので、はじき出しすぎたデータとかがあったのかもしれませんね。
ホント人の手は信用ならないです笑
それにしても、アニメの総作品数が4000とちょっとしか無いというのは私としては驚きです。
アニメ化した作品を書いた漫画化さんたちはどれだけいろいろな人に叩かれようとも、めちゃくちゃすごい方たちなんだなぁって改めて思いますね。
やり残したこと
・未完のアニメや放送中のアニメは現在の放送分までカウント
・時間の計算は各アニメごとの放送時間をとる
放送時間は多分そのうち取れるように改善します。
最後に
この技術を勉強したからと言って私の給料が上がったりすることが皆無なのはわかっていますが、こういうくだらないことを全力でやるって言うのはほんとに楽しい。
今度はドラマの時間とかも計算しよう。
コードもほとんど変えずに使えそうだし。


コメント